The networking in Kubernetes can be pretty complicated and one area that has confused me is the combination of a bare metal Load Balancer and the use of an ingress controller. I have recently deployed this scenario which I will explain within this post.
The end goal is to have a setup that looks like:
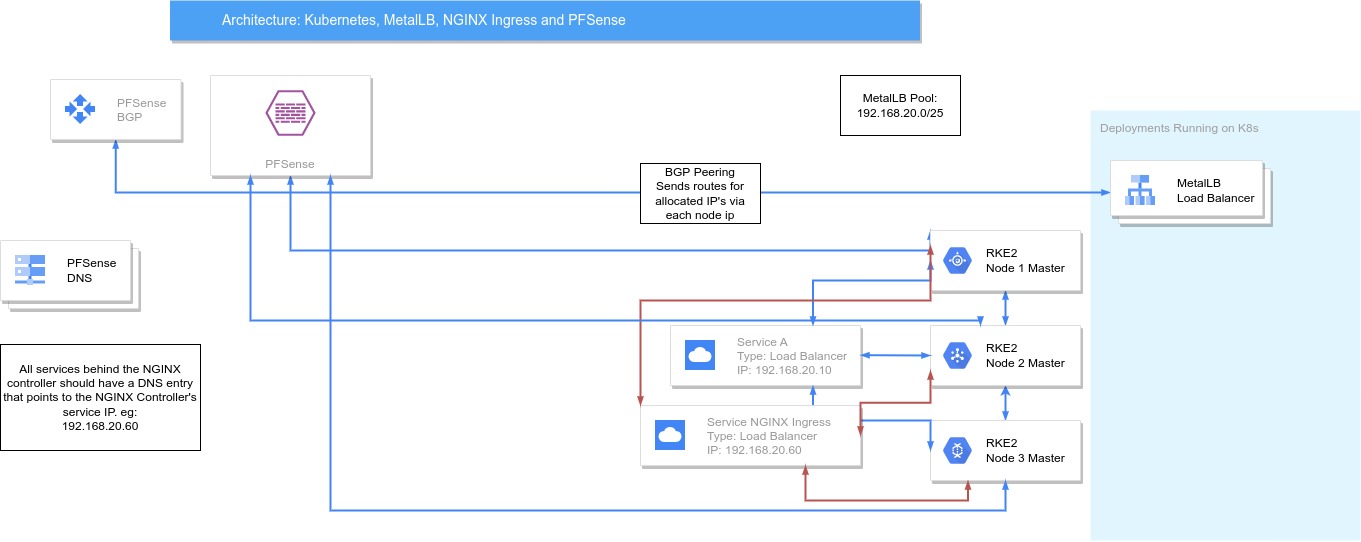
The NGINX ingress controller service needs to be a type Load Balancer. Then all DNS entries for each of your services behind the ingress should point to this external IP.
MetalLB Config
I won’t go into detail about how metallb works as the documentation is pretty good. I will copy some of the example configs here.
Go ahead and deploy metallb. Docs
The following configs should be deployed to your K8s environment.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
apiVersion: metallb.io/v1beta1
kind: IPAddressPool
metadata:
name: default
namespace: metallb-system
spec:
addresses:
- 192.168.20.46/32
- 192.168.20.47/32
- 192.168.20.48/32
- 192.168.20.85/32
- 192.168.20.86/32
- 192.168.20.87/32
- 192.168.20.88/32
- 192.168.20.89/32
- 192.168.20.90/32
- 192.168.20.91/32
- 192.168.20.92/32
- 192.168.20.93/32
- 192.168.20.94/32
- 192.168.20.95/32
autoAssign: true
---
apiVersion: metallb.io/v1beta1
kind: L2Advertisement
metadata:
name: default
namespace: metallb-system
spec:
ipAddressPools:
- default
---
apiVersion: metallb.io/v1beta2
kind: BGPPeer
metadata:
name: default
namespace: metallb-system
spec:
myASN: 64790
peerASN: 64791
peerAddress: 192.168.20.64
---
apiVersion: metallb.io/v1beta1
kind: BGPAdvertisement
metadata:
name: default
namespace: metallb-system
spec:
ipAddressPools:
- default
I have both Layer 2 and BGP advertisements enabled. This is because my services and clients share the same subnet. BGP won’t work for clients on the same subnet as the services because it is layer 3, the client will ARP ping for the IP and receive no reply. The PFSense router will only route to service IP’s via the node IP’s from another subnet. Therefore you need both. I chose to have them on the same subnet because this avoids having large amounts of traffic transversing the PFSense FW which is slower and more resource hungry than dedicated switches.
Metrics (Victoria)
If you use Victoria Metrics then you might want to scrape these.
You need to create an extra service to expose the metrics port.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
apiVersion: v1
kind: Service
metadata:
name: metallb-metrics
namespace: metallb-system
labels:
app: metallb-metrics
spec:
selector:
app: metallb
ports:
- protocol: TCP
port: 7472
targetPort: 7472
type: ClusterIP
Now deploy the Victoria scrape config.
1
2
3
4
5
6
7
8
9
10
11
apiVersion: operator.victoriametrics.com/v1beta1
kind: VMServiceScrape
metadata:
name: metallb
namespace: metallb-system
spec:
selector:
matchLabels:
app: metallb-metrics
endpoints:
- targetPort: 7472
Finally some alerts.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
apiVersion: operator.victoriametrics.com/v1beta1
kind: VMRule
metadata:
namespace: default
name: vmrule-metallb
labels:
app.kubernetes.io/instance: vm
app.kubernetes.io/version: "1.91.0"
spec:
groups:
- name: metallb
rules:
- alert: MetalLBNoLeader
expr: count(metallb_k8s_client_leadership_bool == 1) == 0
for: 2m
annotations:
description: MetalLB has had no leader for the past 2 minutes.
summary: MetalLB has no leader
- alert: MetalLBConfigStale
expr: metallb_k8s_client_config_stale_bool != 0
for: 2m
annotations:
description: '{{ $labels.instance }}: MetalLB instance has stale configuration.'
summary: '{{ $labels.instance }}: MetalLB stale configuration.'
- alert: MetalLBUsableAddressUtilisation
expr: (sum((metallb_allocator_addresses_in_use_total / metallb_allocator_addresses_total)) by (pool) / count(metallb_allocator_addresses_in_use_total) by (pool) * 100) > 75
for: 2m
annotations:
description: 'MetalLB usable address utilisation for IP pool {{ $pool }} is currently at {{ $value }}%.'
summary: 'MetalLB address space utilisation alert.'
- alert: MetalLBNoUsableAddresses
expr: metallb_allocator_addresses_total == 0
annotations:
description: 'MetalLB has no usable addresses.'
summary: 'MetalLB no usable address space.'
Grafana Dashboard
I modified a grafana dashboard to use BGP and Layer 2 stats. It is not perfect but it’s a starting point.
MetalLB Grafana Dashboard - Github
BGP on PFSense
I won’t document all the steps as this guide is pretty good. MetalLB on Kubernetes with pfSense.
Just make sure to change the AS number to match your metallb config.
NGINX Ingress Controller
I am running RKE2 as my K8s cluster and this comes with NGINX ingress controller already deployed. The service exposing it is by default a nodeport. This was the key bit of information I was missing, once you set this to a Load Balancer type then it makes sense how to combine the power of MetalLB and the ingress.
RKE2 allows you to override the deployed helm charts. Open this file or create it if it doesn’t exist.
1
sudo nano /var/lib/rancher/rke2/server/manifests/rke2-ingress-nginx-config.yaml
Add the following contents.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
apiVersion: helm.cattle.io/v1
kind: HelmChartConfig
metadata:
name: rke2-ingress-nginx
namespace: kube-system
spec:
valuesContent: |-
controller:
config:
use-forwarded-headers: "true"
enable-real-ip: "true"
publishService:
enabled: true
service:
enabled: true
type: LoadBalancer
externalTrafficPolicy: Local
annotations:
metallb.universe.tf/loadBalancerIPs: 192.168.20.45
I have some extra bits in here that are not necessary. I want to pass the real client IP to services, hence the use forwarded headers and externalTrafficPolicy. I also use an annotation to explicitly set the IP as it is referenced by DNS.
For all services running with an ingress you need to change the DNS to point to this external IP.
HAProxy
I have configured HA proxy to load balance the kubectl command tool so if one of the nodes goes down then I can still use kubectl without having to change any config. I will also show how I configured it to load balance the ingress before I used metalLB.
Go to Firewall -> Virtual IPs.
Create a new IP; eg: 192.168.20.50/32. Type: IP Alias.
This will the virtual IP to access the K8s nodes.
K8sHA is for the RKE2 nodes to talk to each other on a single IP for the purposes of HA. K8sAPI is for kubectl to talk to active nodes.
Go to Services -> HAProxy -> Backend.
Create the following:
1
2
3
4
5
6
7
8
9
10
Name: K8sHA (or anything you want)
Server List: Add each of the nodes to this table.
Mode: active
Name: Anything
Forwardto: Address+Port
Address: NodeIP
Port: 9345
SSL: no
SSL Checks: no
Health checks: basic
For the API load balancing.
1
2
3
4
5
6
7
8
9
10
Name: K8sAPI (or anything you want)
Server List: Add each of the nodes to this table.
Mode: active
Name: Anything
Forwardto: Address+Port
Address: NodeIP
Port: 6443
SSL: no
SSL Checks: no
Health checks: basic
If you want to load balance on the ingress (not needed with MetalLB and BGP).
1
2
3
4
5
6
7
8
9
10
11
12
13
Name: K8sIngress (or anything you want)
Server List: Add each of the nodes to this table.
Mode: active
Name: Anything
Forwardto: Address+Port
Address: NodeIP
Port: 443
SSL: no
SSL Checks: yes
Weight: Can be the same or higher on one so traffic favours one node
Health checks: HTTP
Http check method: GET
Url used by health check: /healthz
Go to Services -> HAProxy -> Frontend.
For HA.
1
2
3
4
5
Name: K8sHA (or anything you want)
Status: Active
External Address: Select the Virtual IP. Port 9345.
Type: tcp
Default backend: K8sHA
For API.
1
2
3
4
5
Name: K8sAPI (or anything you want)
Status: Active
External Address: Select the Virtual IP. Port 6443.
Type: tcp
Default backend: K8sAPI
For ingress.
1
2
3
4
5
Name: K8sIngress (or anything you want)
Status: Active
External Address: Select the Virtual IP. Port 443.
Type: tcp
Default backend: K8sIngress
Go to settings tab.
1
2
Enable ticked.
Remote syslog: /var/run/log
That should be all what is needed.
If you use HA proxy to load balance the ingress it will hide the client IP. You will need to enable the HA ‘send-proxy’. This can be added under the backend -> advanced -> Per server pass thr. If you enabled this then you will also have to modify the NGINX ingress controller as it will no longer accept traffic sent with ‘send-proxy’.

Comments powered by Disqus.